

Jumping Into the Wayfair Data Jungle: A 2025‑Ready Playbook
Ever stared at Wayfair’s endless aisles and wondered how to pull that gold out without tripping over legal fences or technology roadblocks? In a world where pricing wars are fought in milliseconds and trends morph faster than a cat chase, having a clean, ethical, and scalable data stream is not a luxury—it’s a competitive edge.
Problem Identification: Why the “Wayfair Scrape” is Harder than It Sounds
Wayfair is a JS‑heavy kingdom. Its pages are built on React, and product information is fetched through a labyrinth of XHR calls that shuffle data around like a magician’s deck. Traditional requests bots choke on that. Add to the mix the legal maze—most of the site’s TOS explicitly forbid scraping unless you have a partnership or official API. So you’re left juggling three knives: dynamic content, detection mechanisms, and legal compliance. The solution? A two‑phase, 2025‑ready strategy that starts with the cleanest source of truth (the API) and falls back to a stealth‑friendly browser if the API is off the table.
Core Concepts & Methodologies
- API‑First – Identify and reuse Wayfair’s internal endpoints. Those are often REST or GraphQL, returning JSON that’s a breeze to consume.
- Headless Chrome & Stealth – When the API is out of reach, a headless browser like Playwright or Selenium with stealth plugins can render the JS, while rotating user‑agents and proxies keeps you under the radar.
- Network Interception – Capture XHR traffic to discover hidden APIs or to ensure your page waits for the right data before scraping.
- Politeness & Throttling – Rate‑limit requests, respect
Retry‑After, and add random delays to mimic human behavior. - Error‑Resilient Pipelines – Implement retries with exponential back‑off, and log failures for audit trails.
When you stack those tactics, you’re not just scraping—you’re building a data acquisition platform that can move from prototype to production without breaking every time a new UI tweak lands.
🐍 Python is named after Monty Python, not the snake. Now that’s some comedy gold! 🎭

Expert Strategies & Practical Approaches
- Start with DevTools – Open the Network tab, filter by XHR/Fetch, and watch the product data flow. Often you’ll spot an endpoint like
/api/v2/product/…that returns all the details you need. - Headers Matter – Mimic a real browser:
User-Agent,Accept,Referer, and sometimes custom cookies. A missing header can trip a rate‑limit. - Stealth Flags – Disable automation flags, patch
navigator.webdriver, and randomize viewport sizes to shake off fingerprinting. - Pagination & Infinite Scroll – Either reuse the URL pattern (e.g., page‑2.html) or programmatically click “Next” and wait for
networkidlebefore grabbing the new rows. - Proxy Rotation – Use a pool of residential proxies, and pair them with user‑agent rotation. This reduces the chance of an IP ban and keeps your scrape looking like many unique users.
- Data Normalization – Once you have raw JSON or HTML, flatten nested objects into flat tables (SKU, title, price, availability, image URLs). A clean schema pays dividends when you feed it into BI tools.
Industry Insights & Trends (2025)
- AI‑Driven Extraction – NLP models can now pull structured data from product descriptions, turning free text into fields.
- GraphQL is the New Rest – Many e‑commerce sites pivot to GraphQL for flexible, single‑endpoint queries. Knowing how to craft those queries can save bandwidth and time.
- Browserless Cloud Platforms – Services like Browserless.io let you run headless browsers without managing infrastructure, easing scaling.
- Privacy First – GDPR and CCPA demand that you avoid storing PII. Your pipelines should be built with privacy by design.
- Edge Computing – Running scrapers closer to source reduces latency and can ease compliance with data residency laws.
These trends mean your scraper isn’t a one‑off script; it’s a living system that evolves with the marketplace. Being ahead of the curve could mean the difference between a product that sells out in a day or one that stagnates on the shelf.
⚡ A SQL query goes into a bar, walks up to two tables and asks… ‘Can I join you?’ 🍺
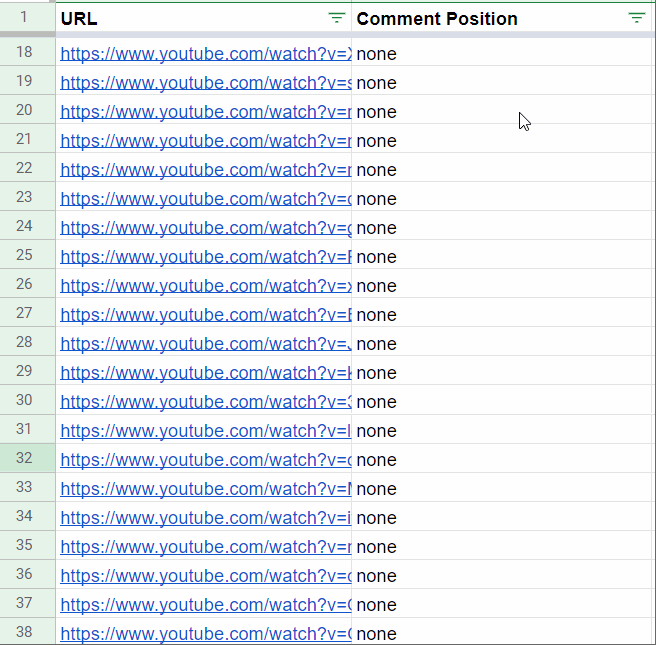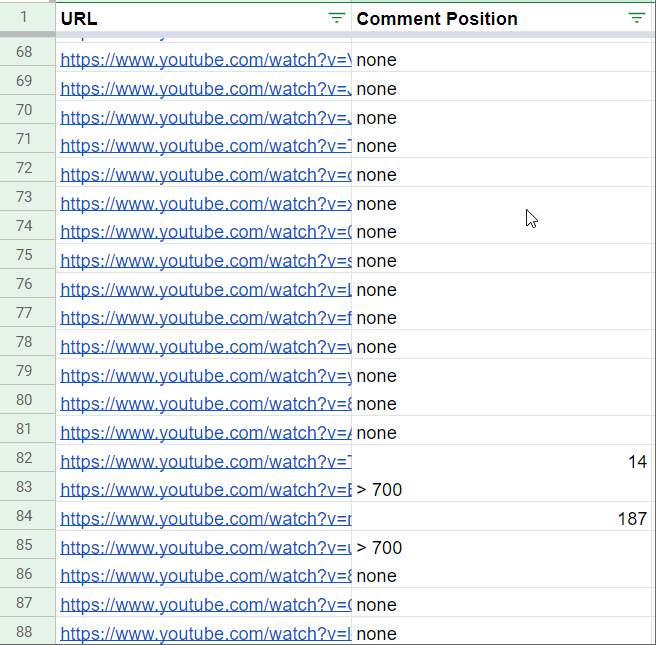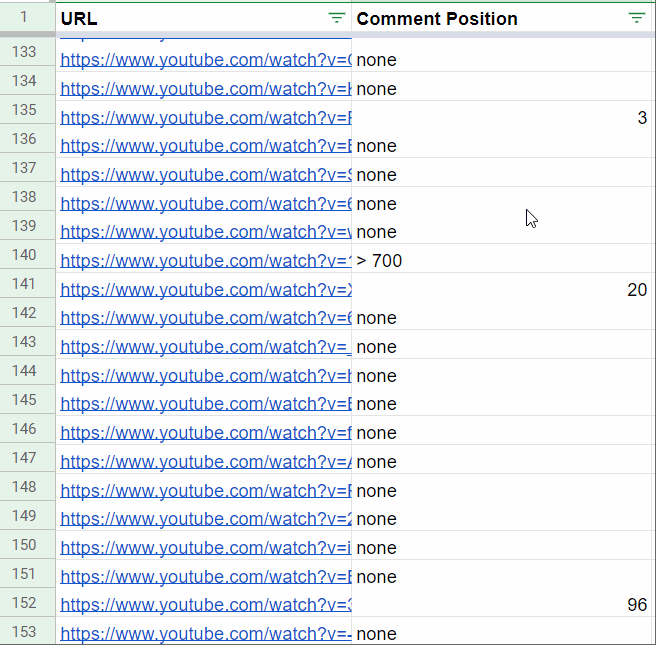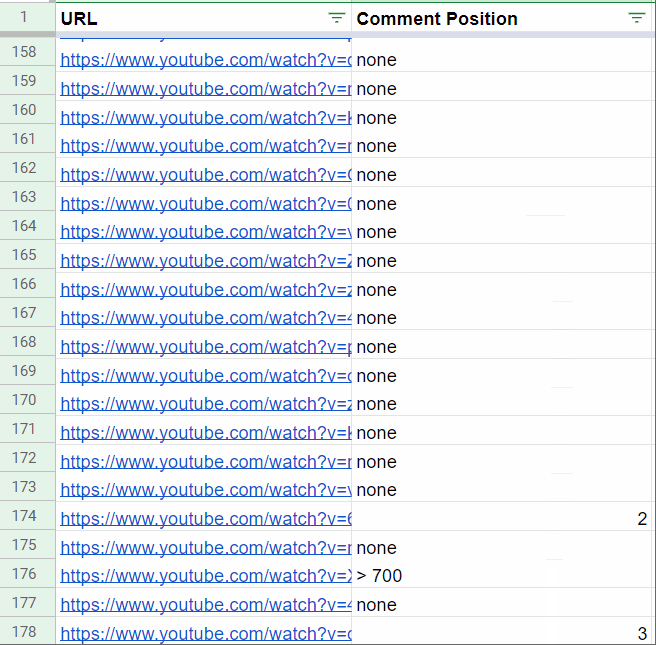
Business Applications & ROI
- Price Monitoring – Keep tabs on competitor pricing in real time. A 1% margin shift can translate to millions in revenue for a large catalog.
- Inventory & Availability Alerts – Spot back‑in‑stock or out‑of‑stock items instantly, allowing dynamic restocking or markdown strategies.
- Market‑Trend Analytics – Combine product metadata with sales data to surface emerging categories, seasonal spikes, and consumer sentiment.
- SEO & Content Optimization – Analyze title tags, meta descriptions, and keyword density across Wayfair listings to refine your own marketing copy.
- Fraud Detection – Detect counterfeit or low‑quality listings by flagging suspicious titles, images, or price points.
Investing in a robust scraping pipeline can yield a payback in days rather than months. For a mid‑market retailer, a single price‑monitoring bot can save tens of thousands annually by preventing price wars and capturing value‑added opportunities.
Common Challenges & Expert Solutions- CAPTCHAs – Rotate proxies, lower request frequency, or use third‑party CAPTCHA solvers.
- Bot Detection – Employ stealth plugins, random wait times, and headful mode intermittently to mimic organic traffic.
- Dynamic Content Loading – Use network interception to wait for specific XHR responses instead of arbitrary delays.
- Rate Limits & IP Bans – Implement exponential back‑off, monitor
Retry‑After, and leverage a healthy proxy pool. - Data Inconsistency – Build selector fallbacks and validate key fields (price, availability) before persisting.
- Legal Compliance – Maintain a log of TOS revisions, document data usage, and consider a compliance audit for sensitive data.
Future Trends & Opportunities
- Server‑Side Rendering Emerging – More sites may expose their data via server‑side rendering APIs, simplifying extraction.
- Edge Scraping Platforms – Expect growth in cloud providers that offer distributed, privacy‑aware scraping.
- Quantitative Data Governance – Organizations will adopt data stewardship frameworks, making clean, auditable pipelines a competitive necessity.
- Multi‑Channel Data Fusion – Combining Wayfair data with in‑store, social, and IoT signals will create holistic customer insights.
Staying ahead means not only mastering current tools but also anticipating where the data landscape is headed. In 2025, the smartest teams will blend machine learning, cloud agility, and ethical frameworks into their scraping playbooks.
Ready to turn Wayfair’s product jungle into your personal data playground? With the right mix of API‑first tactics, stealthy browser automation, and rigorous compliance, you can build a scalable, reliable pipeline that fuels growth, sharpens analytics, and keeps you out of legal hot water.
Need a partner to help you architect, build, and maintain that pipeline? BitBytesLab is a full‑service web and data scraping provider with a proven track record in e‑commerce. Let us turn the data out there into the decisions you need.


